【用pytorch进行LSTM模型的学习】 |
您所在的位置:网站首页 › pytorch 保存整个模型 › 【用pytorch进行LSTM模型的学习】 |
【用pytorch进行LSTM模型的学习】
|
用pytorch进行LSTM模型的学习
LSTM模型用pytorch,采用LSTM对seaborn数据集做预测基本步骤数据的观察特殊数据处理数据归一化模型的构建与选择模型的保存
飞机航班流量预测示例
LSTM模型
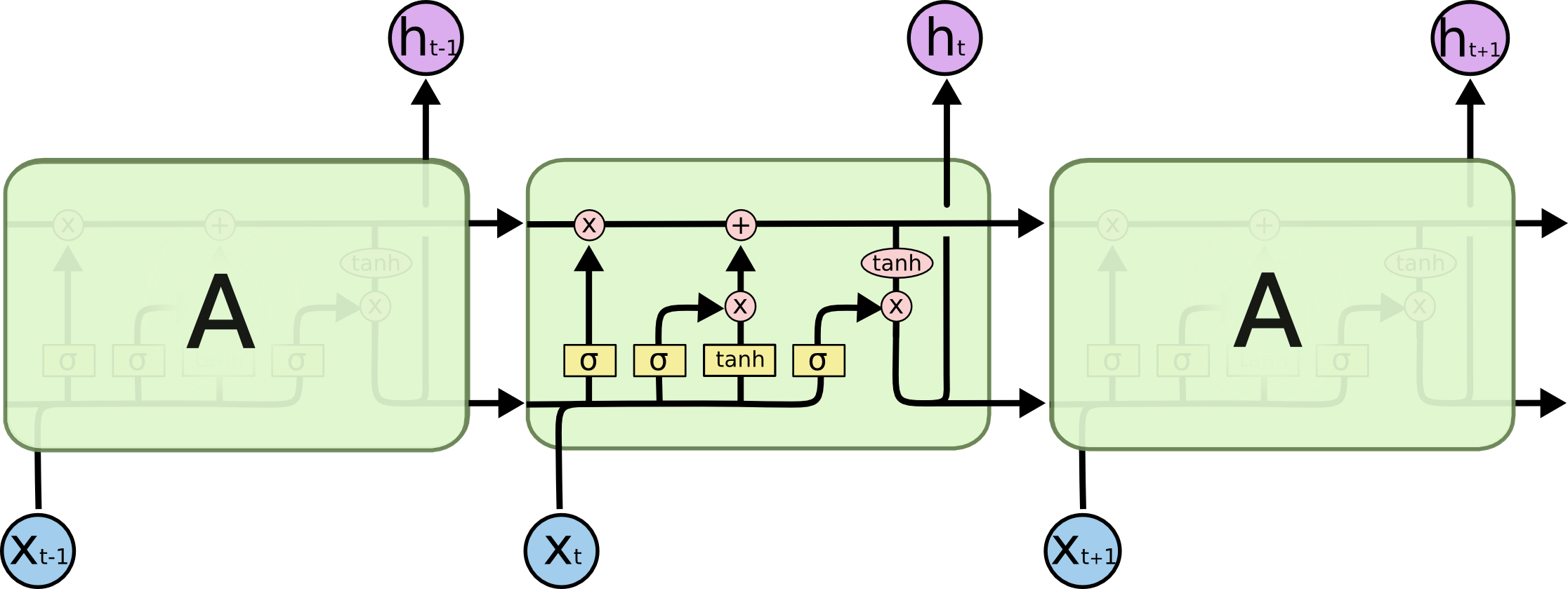
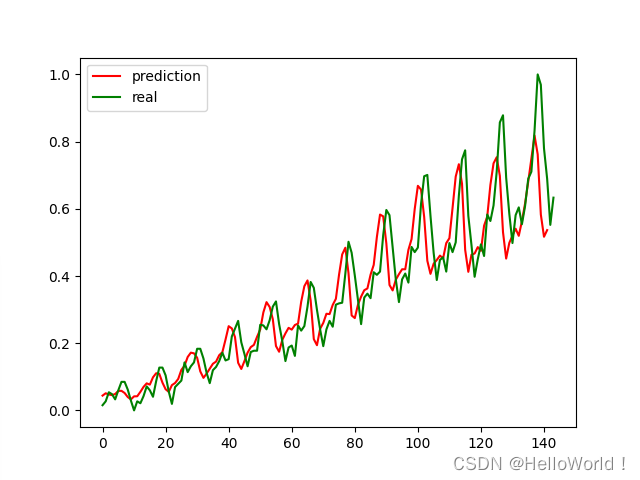
LSTM模型长下面这样,主要用在时间序列的预测,具有比RNN较好的性能。原因在于内部增加了很多门,用来控制前序信息的继续、遗忘、更新等,比RNN更好的表达了特征。 一般而言,进行深度学习的训练与应用包含大概如下步骤 =========工作流程========= - 数据读取与基本处理 * 数据集读取 * 数据的观察-画图 * 特殊数据处理-空值、奇异值等 - 数据集构建 * 归一化 * 训练集、验证集、测试集划分 - 模型建模 * 基础模型架构 * 损失函数 * 优化器选择 - 模型训练 * 模型训练 与各种超参 * 训练过程观察 * 训练中模型保存 * 模型训练指标记录 - 测试验证 * 模型性能验证 * 结果可视化 * 测试性能指标记录下面就流程中的几个重点进行说明 数据的观察在拿到数据的时候,我们首先要对数据进行观察,观察的方法根据数据的类型略有不同,但是总体可以概括为 肉眼观察:打开数据文件夹或者文件进行查看,比如文件个数有多少个,数据的大小是多少。数据展示观察:对于一些不好直接观察的,可以通过数据展示看一下,如打印dataframe结构的前几行,可以看到列名等信息,方便数据处理。画图观察:对于一些时序信息,可以通过作图的方式,看看数据的分布情况,是否有异常点等等。为什么要对数据进行观察?主要有以下几个原因 获取数据的基本信息,知道我们要处理的数据大概是怎样的。对原始数据有个感觉,数据的情况可能会影响我们模型的选择。以及模型训练的策略。比如小样本数据,样本数的多少会影响下一步的决策,如是否数据增强,是否迁移等等。观察到异常情况,如空值,奇异点,为下一步数据处理做准备。 特殊数据处理机器学习处理的是数据的一般情况,即反映数据的一般规律和一般分布,对于奇异值或者特殊值,机器学习模型没有能力处理或者需要付出很大的代价才能处理。机器学习是帮助我们解决一般问题或者共性问题,对于一些特殊的问题,并不是这个学科的主要研究方向。当然,只有一个方向除外,即异常检测。 一般需要特殊处理的,有空值、错误值、奇异值。基本的处理方式有 删除,即删除特殊值补全,补全空值修正,更改错误值 数据归一化在一般情况下,尤其是时序数据,需要进行归一化,即把数据压缩到0-1之间。目的是使得数据有相同的尺度。例如,在一个数据集中,包含样本的年龄信息,收入信息等,这两个信息的度量尺度是不同的,如果不做归一化,那么由于年龄与收入在数值上相差很大,那么年龄的特征不能在模型中发挥很好的作用。 模型的构建与选择针对不同的任务选择不同的模型,有pytorch内置了很多基础模型,因此模型结构的构建变得简单容易,需要注意的是模型的输入参数要求以及维度匹配,这就需要我们学习pytorch内置模型的接口函数,做一个合格的调包侠 模型的保存在训练过程中,模型是不断更新的,每一次迭代后模型的参数就会不同。在这个过程中有必要有条件地保存下当前模型,主要有如下几个用途 防止训练突然崩掉,重新训练浪费资源。在较长时间的训练过程中,由于种种原因,训练可能会崩溃,如突然掉电,机器故障灯,如果没有保存训练过程中的模型,则需要重新训练,那么浪费时间,浪费资源,尤其是接近训练完成的时候发生崩溃,人就更崩溃了。如果保存了模型,那么可以重新加载模型,断点续训练。根据过程中保存下来的模型,我们可以查看模型演变过程,进行过程的考察。测试验证用,保存模型,尤其是保存最后的或者最好的模型,在测试验证时,可以直接加载进行验证,不必再次训练那么模型该如何保存呢? 模型保存的格式:pytorch中最常见的模型保存使用 .pt 或者是 .pth 作为模型文件扩展名。 pytorch模型保存的两种方式: 一种是保存整个模型, torch.save(model, "my_model.pth") # 保存整个模型` 另一种是只保存模型的参数,该方法速度快,占用空间少 torch.save(model.state_dict(), "my_model.pth") # 只保存模型的参数相应的,加载也有两种方式 加载整个模型 new_model = torch.load(PATH) 先构架模型架构,然后加载参数 new_model = Model() new_model.load_state_dict(torch.load(PATH)) 飞机航班流量预测示例完整代码如下 # -*- coding: utf-8 -*- # @Time : 2023/03/10 10:23 # @Author : HelloWorld! # @FileName: seq.py # @Software: PyCharm # @Operating System: Windows 10 # @Python.version: 3.8 import torch import torch.nn as nn import argparse import seaborn as sns import numpy as np import pandas as pd import matplotlib.pyplot as plt import math # 数据读取与基本处理 class LoadData: def __init__(self,data_path ): self.ori_data = pd.read_csv(data_path) def data_observe(self): self.ori_data.head() self.draw_data(self.ori_data) def draw_data(self, data): print(data.head()) fig_size = plt.rcParams["figure.figsize"] fig_size[0] = 15 fig_size[1] = 5 plt.rcParams["figure.figsize"] = fig_size plt.title('Month vs Passenger') plt.ylabel('Total Passengers') plt.xlabel('Months') plt.grid(True) plt.autoscale(axis='x', tight=True) plt.plot(data['passengers']) plt.show() #数据预处理,归一化 def data_process(self): flight_data = self.ori_data.drop(['year'], axis=1) # 删除不需要的列 flight_data = flight_data.drop(['month'], axis=1) # 删删除不需要的列 flight_data = flight_data.dropna() # 滤除缺失数据 dataset = flight_data.values # 获得csv的值 dataset = dataset.astype('float32') dataset=self.data_normalization(dataset) return dataset def data_normalization(self,x): ''' 数据归一化(0,1) :param x: :return: ''' max_value = np.max(x) min_value = np.min(x) scale = max_value - min_value y = (x - min_value) / scale return y #构建数据集,训练集、测试集 class CreateDataSet: def __init__(self, dataset,look_back=2): dataset = np.asarray(dataset) data_inputs, data_target = [], [] for i in range(len(dataset) - look_back): a = dataset[i:(i + look_back)] data_inputs.append(a) data_target.append(dataset[i + look_back]) self.data_inputs = np.array(data_inputs).reshape((-1, look_back)) self.data_target = np.array(data_target).reshape((-1, 1)) def split_train_test_data(self, rate=0.7): # 划分训练集和测试集,70% 作为训练集 train_size = math.ceil(len(self.data_inputs) * rate) #math.ceil()向上取整 train_inputs = self.data_inputs[:train_size] train_target = self.data_target[:train_size] test_inputs = self.data_inputs[train_size:] test_target = self.data_target[train_size:] return train_inputs, train_target, test_inputs, test_target # 构建模型 class LSTMModel(nn.Module): ''' 定义LSTM模型,由于pytorch已经集成LSTM,直接用即可''' def __init__(self, input_size, hidden_size=4, num_layers=2, output_dim=1): ''' :param input_size: 输入数据的特征维数,通常就是embedding_dim(词向量的维度) :param hidden_size: LSTM中隐层的维度 :param num_layers: 循环神经网络的层数 :param output_dim: ''' super(LSTMModel,self).__init__() self.lstm_layer=nn.LSTM(input_size=input_size,hidden_size=hidden_size,num_layers=num_layers) self.linear_layer=nn.Linear(hidden_size,output_dim) def forward(self,x): x,_=self.lstm_layer(x) s, b, h = x.shape x = x.view(s * b, h) # 转换成线性层的输入格式 x=self.linear_layer(x) x= x.view(s, b, -1) return x #模型训练 class Trainer: def __init__(self,args): self.num_epoch =args.num_epoch self. look_back=args.look_back self.batch_size=args.batch_size self.save_modelpath=args.save_modelpath #保存模型的位置 load_data = LoadData(args.filepath) # 加载数据 self.dataset = load_data.data_process() # 数据预处理 dataset = CreateDataSet(self.dataset , look_back=args.look_back) # 数据集开始构建 self.train_inputs, self.train_target, self.test_inputs, self.test_target = dataset.split_train_test_data() # 拆分数据集为训练集、测试集 self.data_inputs = dataset.data_inputs #改变下输入形状 self.train_inputs = self.train_inputs.reshape(-1, self.batch_size, self.look_back) self.train_target = self.train_target.reshape(-1, self.batch_size, 1) self.test_inputs = self.test_inputs.reshape(-1, self.batch_size, self.look_back) self.data_inputs = self.data_inputs.reshape(-1, self.batch_size, self.look_back) self.model=self.build_model() self.loss =nn.MSELoss() self.optimizer=torch.optim.Adam(self.model.parameters(), lr=1e-2) def build_model(self): model=LSTMModel(input_size=self.look_back) return model #训练过程 def train(self): #把数据转成torch形式的 inputs= torch.from_numpy(self.train_inputs) target=torch.from_numpy(self.train_target) self.model.train() #训练模式 #开始训练 for epoch in range(self.num_epoch): #前向传播 out=self.model(inputs) #计算损失 loss=self.loss(out,target) #反向传播 self.optimizer.zero_grad() #梯度清零 loss.backward() #反向传播 self.optimizer.step() #更新权重参数 if epoch % 100 == 0: # 每 100 次输出结果 print('Epoch: {}, Loss: {:.5f}'.format(epoch, loss.item())) torch.save(self.model,self.save_modelpath+'/model'+str(epoch)+'.pth') torch.save(self.model, self.save_modelpath + '/model_last' + '.pth') self.test() def test(self,load_model=False): if not load_model: self.model.eval() # 转换成测试模式 inputs = torch.from_numpy(self.data_inputs) # inputs = torch.from_numpy(self.test_inputs) output = self.model(inputs) # 测试集的预测结果 else: model=torch.load(self.save_modelpath+ '/model_last' + '.pth') inputs = torch.from_numpy(self.data_inputs) # inputs = torch.from_numpy(self.test_inputs) output =model(inputs) # 测试集的预测结果 # 改变输出的格式 output = output.view(-1).data.numpy() #把tensor摊平 # 画出实际结果和预测的结果 plt.plot(output, 'r', label='prediction') plt.plot(self.dataset, 'g', label='real') # plt.plot(self.dataset[1:], 'b', label='real') plt.legend(loc='best') plt.show() if __name__ == '__main__': filepath ='seaborn-data-master/flights.csv' save_modelpath='model-path' parser = argparse.ArgumentParser(description=__doc__) parser.add_argument('--num_epoch',type=int, default=1000, help='训练的轮数' ) parser.add_argument('--filepath',type=str, default=filepath, help='数据文件') parser.add_argument('--look_back', type=int, default=2, help='根据前几个数据预测') parser.add_argument('--batch_size', type=int, default=2, help='batch size') parser.add_argument('--save_modelpath',type=str, default=save_modelpath, help='训练中模型要保存的位置') args=parser.parse_args() train=Trainer(args) train.train() train.test(load_model=True)结果如下 |
【本文地址】
今日新闻 |
推荐新闻 |